This is a mirror of my post in Medium.
 Figure: Photo by Krzysztof Kowalik on Unsplash
Figure: Photo by Krzysztof Kowalik on Unsplash
So, after more than two years it is time to return to complete the trilogy and answer the critical question: “How does the industry feel now that the dust has settled and the occupational honeymoon has ended?” In short; still loving it, but do read on for details.
In this third part I’ll focus less on the differences between the academia and the industry and discuss more on how the industry feels in the long run ‘from the inside’. I’ll describe what I’ve been up to and how I’ve evolved. Besides these, the text also ended up including a long-ish discussion on ‘Business’ from a technical person’s point of view. I’m hoping for it to be useful to those who wonder what the requirements of “business understanding” mean when applying for positions, but you should be wary of the content as I am not an expert on whatever ‘Business’ actually is.
As before, the caveats of these writings stack up. I see all of this through the experience of this singular narrative that I’m living, YMMV.
Introduction
I’m happy that I wrote the earlier parts of this trilogy during the transition as I am getting more and more hazy on remembering why the current situation felt different than before. I also think that the usefulness of these posts is decreasing at an exponential rate for the same reason I think that for the Analysis 101 classes it is good to have somewhat young students as course assistants. C.S. Lewis put it well when he said “The fellow-pupil can help more than the master because he knows less. The difficulty we want him to explain is one he has recently met. The expert met it so long ago that he has forgotten.” So I would suggest treating the first part of this trilogy as the most significant one and parts 2&3 as kinds of curious addendums. Or maybe as comforting tidbits that tell you that even years after transitioning I’m still happy with no regrets.
Despite these warnings that I’ve forgotten a lot of how it was before the industry, all has not been lost. As a good refresher last spring, a bit before my 2 year mark at the company, I got the honor to be the opponent of a former colleague’s doctoral defense. This gave me the excuse to really go deep into math and helped me recall some of the feeling I had while working in the academia. It also helped me to remember some of the contrast between the two worlds.
But besides this and some other small excursions, I’ve now pretty much settled to my own personal new normal as a cog in the machine. A big reason for this feeling at home is a combination of close new colleagues, the ingestion of a thousand little skills, and all the silent knowledge that I have been able to amass. I can’t properly verbalize all or even most of the little and big things that I’ve learned, so the rest of the article will not be a very long list of bullet points. Instead I will try to describe some of the bigger ideas I’ve learned that I think would be useful for others to know as well.
 Figure: DALL-E’s rendition of (me as a) a cog in the machine.
Figure: DALL-E’s rendition of (me as a) a cog in the machine.
Setting the scene — What have I been up to?
For the past year and a half or so I’ve been largely working on two overlapping projects: as the lead data scientist on one long major project, and as the lead data scientist slash part-time project manager of another six-month project. This has been in contrast to the start of my career here when I would work in supporting roles on various projects, sometimes in parallel, for various amounts of times going from 1 to 6 months. In general seeing the larger arc of a project going from planning to execution, deployment, hypercare and finally to quarterly status review meetings has been enlightening, but let’s look at each of these two major projects in detail.
The longer project — Medical NLP
Of the two mentioned above, this is the one I consider the main one. It is in the field of medical AI, largely in NLP and classification, and I’ve been the main ML-architect/developer responsible for creating various ML-solutions together with large parts of the system architecture. It was the first project where I got to start working from scratch. This project introduced me to a whole new set of interesting challenges, some of them technical considerations in ML-engineering and MLOps/DevOps, but also many of them in the legal, bureaucratic and ethical side of things. The latter stem from the fact that EU in general and Finland in particular takes a very strict view on handling peoples’ medical data and on having computer programs being involved in patient care. As a human and a citizen I’m really happy on the level of scrutiny we had to go under, even though at times my data scientist side was feeling impatient to get some data in our hands. In the end I believe that that impatience was just growing pains and an important part of being a data scientist in a given field is to grow accustomed to the realities of the subfield. The project went and is going well, and largely in honor of this I was even given the title of “Healthcare Industry AI Lead (Data Scientist)”. This did not bring me any new responsibilities, but was more of a reflection on the position I had gravitated into.
It would be really hard to try and enumerate all the things, or even all the important things, that I learned in this project, but the two lessons that I really want to highlight here were that data is not always abstract, and that classification is not a discrete problem. The first lesson stems from the fact that in order to do proper data science work it is really important to familiarize yourself with the data. In this project with the data being related to medical conditions I got to have very long discussions with medical professionals about many of the different ways people can be broken and how they might be then fixed. The most sobering experience for me was having a discussion where I asked why a given class of data was so underrepresented compared to others and a doctor told me that the class was related to such a severe a medical condition that the people affected would usually perish before producing more data for the class. So nowadays the term “imbalanced classes” brings to my mind not only SMOTE and other clever techniques but also the human condition. I think this is a very positive and humane evolution for me which helps me remember that the things I do are not just fun intellectual exercises but actually touch human lives.
For the second lesson about classification not being a discrete problem, let’s look at the classical task of “Classify the incoming data to given classes.” At the surface this sounds like a very straightforward problem that we’ve seen before in various ML-tutorials or other study materials. With a bit more advanced material you might even get some mentions about some percentage of the data being mislabeled, or that the ground truth might rely on the vote of a committee of human experts who might not always agree. In some cases you might even look at situations where there wasn’t a perfect one-to-one mapping between the set of labels and the set of classes that exist in reality. What I wasn’t at first prepared for at all was the fact that for some some data there simply isn’t one correct category where the datum might belong to. The problem gets interesting when every datum at hand does receive a label, but some of those labels might contain the unnamed classes of “this case requires more information to classify” or “this datum could belong to various classes”. Many of the technical challenges this poses can be solved with the same tools that handle mislabeled data, but conceptually the difference is quite big and needs to be discussed with the people actually involved in using the system. In the end the single most import tool in these types of cases has been increased communication with the client’s subject matter experts together with extended meetings with the stakeholders about the situation. (In a majority of AI-related issues, the best solution, or at least a very important part of the solution, tends to be ‘increased communication’.)
The shorter project — Custom data extraction
The shorter parallel project was a bureaucratically less heavy custom AI-project related to structurizing data from video sources. I had less to do with the more complicated AI-components, but instead had my responsibilities focused on customer interactions, system architecture and managing the ML-work of a few other data scientists. The data scientist management side of this project was not very remarkable as I have highly skilled and very self-sufficient colleagues, and my managing of them constituted mostly of describing a problem and then waiting a few days for a solution to pop up. One of the more interesting technical sides of the project was, however, on how to build a system that has several components built by various people. On these topics I don’t have such clever insights to share yet, but in general I would here give a shout-out to the Mythical Man-Month.
The project also provided learning possibilities in the more technical side of things. I had used Docker in various settings before to encapsulate various solutions and whatnot, but it was during this project that I really got a chance to dig deep to the world of docker-compose. (A big recommendation to Poulton’s book on the topic.) Organizing a multi-container system with innards made by various other people was a delightfully complicated process and it was incredibly rewarding (not to mention initially a bit surprising) to see the whole pipeline work.
All the other things that I’ve been doing
Aside from these two big projects I’ve spent maybe 10–20% of my work time to various other things that can only be classified as a bucket labeled “Misc.” I don’t want us to lose the forest for the trees so I won’t delve here in detail, but I don’t want to omit it completely either.
This bucket of misc does include some shorter projects where I have provided some consulting or other small help with creating AI-components, but that is not all. Just as there is a lot more to ML-work than just doing technical stuff with data and models, there is a lot more that I have on my table than just working on singular projects. As an ‘expert explainer’ I am often involved in both internal and customer facing meetings where the possibilities and limitations of AI are discussed together with various estimates on how much work and time it might take to produce a given solution. I’ve also had the semi-official responsibility of familiarizing myself with many out-of-the-box AI-solutions that the major providers in our field are offering so that we can better understand which tools are available and how they compare.
For me the most interesting types of tasks here tend to be those where I get to take part in the more strategic discussions — looking at what might be the big directions in which AI might be used by the company in the future. Besides strategical discussions, these kinds of smaller variable tasks are not my main focus, nor are they my favorite kinds of tasks to do, but they are still usually fun to do. At minimum they provide some variation on the daily grind. And I do usually seem to thrive better than many when given unusual tasks with no clear existing guidelines — Jack of many trades and master of one?
 Figure: DALL-E generated cubistic painting of Business.
Figure: DALL-E generated cubistic painting of Business.
Thoughts on ‘Business’
Here I want to talk about Business with a capital B. The motivation comes from when I was still in the transitioning phase and in many places I would see this requirement that Data Scientists should understand not only Programming and ML but ‘Business’ as well. And this would cause me some concern. Whenever I would get the feeling that “I need to understand programming better.” or “I need to understand ML better.” I could, with slight hyperbole, just grab a book called “Introduction to Programming/ML.” and start reading. But it didn’t seem that there were clear technical manuals called “Introduction to Business.”, and when there were, they all seemed to discuss different topics with languages that were strange to me.
Now, after a few years, I think that I have an instinctive feeling of what it seems people meant by ‘understanding business’. Maybe. The concept is still a bit ephemeral to me, but I’ll try to explain here some views and concepts to hopefully pass on useful information to fellow non-business background Data Scientists about what it is that some people are after. Here I talk with much less confidence than in some other areas, so take this with a grain of salt — what ever the platonic ideal of ‘Business’ is, I’m not an expert in it.
As an additional caveat: this part has also been described as ‘somewhat adorable’ and ‘bravely honest about my level of understanding’ by some of my proofreaders who have spent more time outside the bubble of Academia. So if it feels like a section filled with naive truisms, you should probably skip it. I’m still hoping that it will serve some purpose to those (of us) who’ve spent many years in the academical world, shielded form things like profit margins.
Why are Data Scientists concerned about ‘Business’?
Before getting to ‘Business’, there’s gonna be a small rant about the concept of defining things outside the world of pure mathematics, with a certain Venn-diagram as the specific target.
So there is this sort of classical Venn-diagram on “what is data science” which I think describes what we would like data science to be, or at least what I personally would like to claim I know as a Data Scientist — deep knowledge in all three fields of Math&Stat, CS and Business.
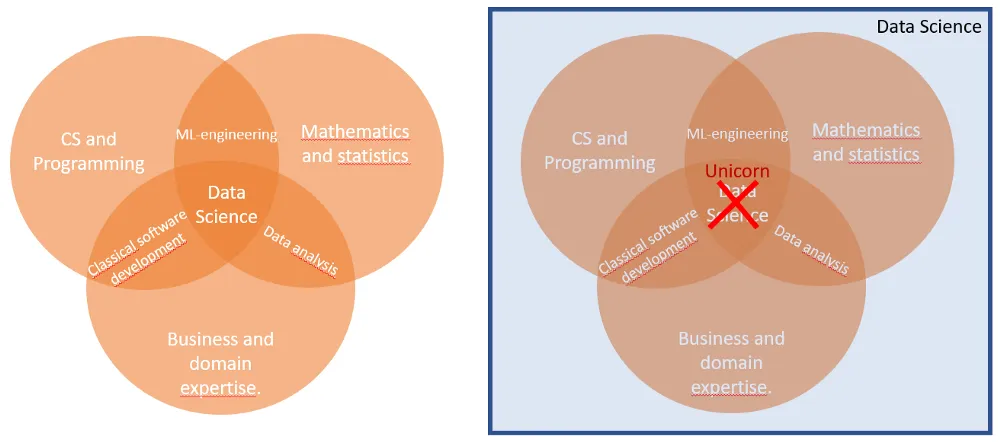 Figure:
Left: Data Science as the intersection. Right: Data Science as the union (and them some). Not Pictured: The concept that this whole approach of trying to define Data Science is flawed.
Figure:
Left: Data Science as the intersection. Right: Data Science as the union (and them some). Not Pictured: The concept that this whole approach of trying to define Data Science is flawed.
I am not the first one to note that this diagram has some shortcomings, some of them more nuanced like “Data Science is it’s own field that shouldn’t be defined only through other fields no more than mathematics should be defined as the intersection of Numbers and Theoretical Philosophy.” and some of them more practical like what I’ll discuss here. To my eyes the term “Data Science” is more of an umbrella term and I’ve met with data scientists working inside (and outside) of all the areas of the above Venn diagram, not only in its intersection. That being said, there is of course some grain of truth here as admittedly the various subjects mentioned in the diagram can be very useful in data science projects. I think that this diagram should be in the same box as the Bohr model for atoms — good as a first approximation to show to new people, but served with caveats in bold red letters.
One big particular practical grievance I have with this diagram is the more generic notion that outside of mathematics terms and words are not defined via singular definitions you find in dictionaries or diagrams but by their use in the real world. When linguists put together grammars, they are not making up rules on how to use the language, but creating a record on how the language is used. And similarly for definitions of words in dictionaries. In my mind this idea applies very strongly to data science — we are still more or less figuring out what the different tasks are that a Data Scientist might do, and what titles might we use to give more specific information on the responsibilities and competencies of a particular data scientist. So even if these types of diagrams and guides provide useful information, I would approach them as descriptions of what we’ve observed data scientists doing in the wild instead instructions or requirements that should be enforced.
A related element here is that since the exact content of the field of Data Science seems still be quite fluid, the phrase “it’s not what you know now but what you can learn to do” rings even more true. You might get to do very different kinds of things under the umbrella of data science, both in the technical and more general sense, and having the ability to learn and adapt quickly can be huge benefit.
So with my rant about the Venn diagram that originally brought ‘Business’ to my study to-do list over with, let’s move on to discussing what the strange blob of ‘business’ in these types of diagrams might mean. Because despite the shortcomings of definitions and diagrams, I do feel that understanding ‘Business’ better has made me better at what I do. I am not even going to attempt to give any sort of definition, but instead we are going to look at a few different example cases, and hope that there is some concept that you can gleam as the actual thing from which these are just a sampling.
A practical example — “distance to product”
In short, “distance to the product” is pretty much what it says on the tin: how close are you to the ‘product’ i.e. the thing that your company trades for money? This can have a huge effect on how much salary or appreciation you can get, especially in times when the economy is feeling low and people want to prioritize the immediate profits compared to long term strategic goals.
As an example, using Data Science skills to help the board understand strategical long term trends in the company turnover is important, but in a pinch the actual ML-based software solution that will bring your company immediate income every month might take precedence when your company wants to report quarterly earnings. Naturally the situation is never as simplistic as “immediate money good, long-term planning bad”, but a big part of the idea here is to know where you stand and try to keep up where the company’s current priorities lie. Furthermore being aware of the concept of distance to product can be very fruitful as it is can help you to understand the business model around and behind what you actually do day to day. This in turn can help reduce any remnants of Fraud Syndrome you might have, as you can clearly see how you’re making more money/value to the company than they are paying you. (Personally, seeing this reduces my fraud syndrome levels, but if instead it makes you feel like you should be cutting out the middle man, you might enjoy some of the essays in Graham’s book.)
A practical example — your company’s business model/idea
You don’t need to speak fluent corporate or understand the details of how quarterly earnings are reported, but you should try to get a rough feeling on what makes your company tick. Some stuff you might want to figure out, e.g. from listening monthly townhalls might be things like:
- Where do the profits come from? Are you getting your main income from consulting, or selling software products, or from service fees to your solutions portal? Is the majority of your revenue from existing customers who will keep paying the same amount every month for the foreseeable future, or do you rely in constantly getting new customers who need your services?
- What is the field or subfield in which you operate? Do you provide services for customers or for other businesses? Are you a major player in this field and if not, then what is your competitive advantage? Who are your competitors?
This is essentially on the same spectrum as “distance to product”, but on a different scale with distance to product discussing your position relative to the company, and the business model discussing the position of your company relative to the world.
A practical example — ROI
Many companies, especially younger ones, rely heavily on investors putting money in the company so that the company can e.g. expand.* The investors are taking a risk since your company might go under, and to compensate for the risk they will want to get better returns for their investment than they would get from more secure investment options. This means that it’s very rarely enough for a company to just break even — you want to consistently make more money than you are spending, by a margin that is better than your standard index fund. Also when you are planning to start a new project with a customer, you have to take into consideration the risk that the project doesn’t pan out for some reason, and that the profits from the particular project will also have support the running costs of the company like office rent and HR salaries. I’m personally very happy that I’m not the one who has to do these calculations, but understanding the basics can help you see why the company might favor some projects over others.
In some sense this is again a variation on the two earlier points, or maybe another perspective on the position that you have in the company and the company in the wider world. And it can be crucial for you to understand if you are involved in project planning — partially because you’ll understand the context better, and partially because you’ll probably be taken more seriously if you can demonstrate that you’re not clueless to the market realities.
* ”Why doesn’t the company wait until it has ‘naturally’ generated enough excess profits and use those for expansion?”, I hear you ask. One reason might be that there are new markets opening up and if you wait a year to expand 10%, your competitor will have already scooped all the new possibilities up by taking in investments to expand by 100% in a month, to give an exaggerated example.
‘Business’ in summary
I don’t think I can properly summarize what I have in my head when I think ‘business’, but hopefully the three examples above can give some insight to what I think might be useful for a data scientist to know. The ability to learn new stuff without things explicitly spelled out for you, picking ideas up from the context you are working in, can be immensely valuable here.
If all of the things mentioned above were basic information to you, then I say well done you! For me most of this was far from obvious when I started. A lot of this stuff is just things I picked up along the way, and it might be distorted or plainly wrong compared to what actually is going on in the business world so please, again, take it with a very big grain of salt.
As I mentioned earlier, I haven’t found a singular book that I would consider a good “Introduction to Business”, but if you’re like me and would really like to have a book to read on the topic, I did enjoy reading Friedman’s Hidden Order when I was a grad student. I would maybe start with this and/or look at the reviews to see which books people think are better and go from there.
My technical evolution
In a previous post on this trilogy I mentioned how I was excited on how much more natural programming, especially in Python, has turned into in only a few months and how I was curious to see where I would be at the 2 year mark. It’s now a bit beyond that, and the feeling is good. This section is the most me-specific and self-serving, but I’ve tried to include some general ideas about learning that might be beneficial to others than me as well. So let’s look at a few different areas to see how one might advance when they do this kind of thing for a few years on a daily basis.
Python code quality
Python is still the language of choice for me with 99% of the code I write being Python, though I’ve dabbled in Java, JavaScript and C# for various projects. I’ve gotten opportunities both during projects and time for personal training to improve myself in Python, and I think it is really starting to show.
I don’t think that there is a very big need for me to try and specify my exact skill level in Python, but there are some aspects in it that I want to try and explain. One fundamental feeling I have about my particular skills is related to something I call ‘the generic programming language’. This is kind of like the ‘pseudocode solutions’ you see sometimes as answers to algorithm design problems, where you write generic loops and conditionals to bring the general idea across without actually fixating to a particular language. I feel that once I learned to program in the first few languages I came across (hello TI-BASIC, Java and MatLab) my brain kind of abstracted this general idea of what most programming languages do. (Note that I was raised on descendants of Fortran/C instead of languages like LISP, Haskell or APL which must have a huge effect on my conceptual idea on programming.) After you get the first few languages under your belt, you can quite quickly adopt new languages on the most basic level where you are just writing these generic pseudocode solutions — to write a json parser in C# I just needed to learn the base syntax and how iterators are used and I was pretty much there. But that doesn’t mean that I learned C# in a day, since I am only using it at this generic way that I would use any other similar language whose syntax I’d studied for a week. I don’t actually know how to use C# in the native C# way, and I think that this is a very crucial difference when I’m reflecting on my own programming skill.
In any case, what I’m driving at here is that with Python I think I’ve gone way past this post, meaning that when I write python code I write Python instead of just ‘generic programming with Python syntax’. I’m not yet at a level that I would consider mastery of the topic, especially due to my lacking of understanding of the Python internals, but I feel that I am starting to get the main idea. What would really help me for next steps, and what I hope to do in the near future, is to get on a comparable level with another language so that I could compare on the similarities and differences properly.
Increased system complexity
This is less Python specific and more about what kind of systems I build and what kind of tools I use to build them. I’ve gone from Emacs/vi to VS Code and from singular script files to using docker-compose to build multipart systems that enable large asynchronic pipelines with multiple AI and non-AI components. I’ve also spent enough hours to re-invent a few of the common wheels and I think I’m slowly learning that it really does pay off to learn how to use e.g. FastAPI instead of building my own (worse) version from scratch.
Combining the increased system complexity with the fact that I’m at the same time getting more and more familiar with the cloud stack and how networks work or don’t work (it’s always the DNS), I am at times starting to think if it would be cool to push myself even deeper in the architecture side and towards being Full Stack. Though at the same time I also kinda think that a “Full-Stack Data Scientist” is a bit like Santa Claus: they don’t actually exist, but once in a while it’s nice to have someone put on the red dress with a fake beard to play the part. Especially as this usually provides the service that people *actually* need even though originally they were asking for a capitalist demigod equipped with supersonic reindeer.
ML-mindset
A lot of the important points about my growth in the ML-side of things were already mentioned when I discussed the medical NLP-project I had been working on, but they are a part of a larger theme, I think. This probably again goes to the more general theme of having an intuitive sense of what I am doing, what the customers are usually expecting (and actually need) and what the current tools can accomplish.
Here I can offer the least advice or suggestions on what to read or do, except for very generic and borderline unhelpful banal things like “work with messy data” or “try to get involved in actual ML project from project planning stages to hypercare”. One singular good advice that prof. Roos keeps repeating is that whenever you do ML stuff:
Always start with an easy and simple model to establish a baseline.
And I feel this advice is good enough to repeat any time I get the chance. If you are doing a complicated NLP classification project, just do a quick wordbag + decision tree/forest -solution to get some sort of idea how the thing goes. Or any other prebuilt model you get from scikit-learn or Azure AutoML. It’s easier to try and understand if the 86% accuracy of your hypertuned transformer is good or not if you decision tree is hitting an 82% accuracy with 0.01% of the resources.
How can you keep learning?
This is less on what I’ve learned and more on how I was able to keep learning. I’ve had various people reach out to me after the previous posts to ask me further questions, many of which have been now included in this text, and a few have been asking me how to keep learning in the industrial world and not get stuck doing just one thing. There is, naturally, no one single answer on how to keep learning, but I do strongly suggest you do. There’s this one cool reddit story about the folly of ‘Dapper Dan’ that mentions the following advice:
“Each job pays you twice. You get your money now, that’s your wage. You also get experience now, that’s how you get paid in the future. So. Are you still getting paid? Yes? Are you still learning? No? Figure out how to keep learning, or leave.”
And this is something I largely agree upon. It doesn’t mean that every day of every week you should be getting to study fun new topics, but I think it’s good to keep a little monthly or quarterly check with yourself to see if you have been able to improve yourself, be it in technical topics or something more generic like ‘getting better at handling customer expectations’. The amount of learning you want to keep doing is, of course, a subjective thing, but it would be good to be at least aware of what is actually happening.
Personally I’ve been once again lucky as the company I work for is quite supportive of my continuous learning efforts, so in particular my advice might not transfer well. In any case, my first hint here again ties to the earlier discussions on ‘business’ — if you are involved in project planning and timeline estimations, you can more easily try to sell the idea that a few days of the long project could be directed to you learning a new tool to help with the task. Or if you see that the company strategy is shifting, you can try and sell that in order to support the new directions it would be beneficial for you to be trained in X, for example during the next quarter when the company is estimating the business to be slow anyway. Selling these ideas is much easier when you have a grasp of what the company in general is valuing and doing.
Thoughts on math
So how’s the math after two years? Surprisingly good, I would say. Admittedly I have no essentially new publications, but I’ve been able to get myself involved with both mathematics and mathematicians. The latter part in particular has been important for me, since the one thing I do miss is he mathematicians’ community and e.g. the way you can randomly end up spending half of your 12-hour work day in the department coffee room, discussing and debating the root cause why 3-sided dice with straight faces cannot exist in our world/geometry, interspersed with horrible topological puns.
But luckily I am not completely cut off from the terrifying beauty that is the math department coffee room culture. As briefly mentioned above, last spring I got one of the highest honors one can get after getting their PhD — I got to be an opponent for someone defending their thesis. This made me quite happy in many ways, not the least being the feeling that I’m still being considered as a part of the mathematical community. Getting to be the opponent is a bit being like a godfather in that you can’t really go around and ask if someone would take you, you have to wait to be asked. And not everyone gets asked. In addition the more humane benefits of getting to do this, there was the more technical advantage that I finally had a proper reason to really delve into mathematical publications. And not just skimming them, but actually studying them to the level of questioning the results, which is no mean task for research-level math. This felt good, in part because the papers were actually remarkably good and on interesting topics, and in part because it was good to see that I still had it in me to understand them.
Besides this one big endeavor I do sometimes read exciting math either from my own field (I still subscribe to Arxivist) or exciting things that I happen to come across, but more to satiate my own curiosity rather than at the level of trying to create something new. I do sometimes pick up old big conjectures that I used to work on, just to see if time would have brought me a new perspective, but I don’t harbor any actual belief that I might be able to actually solve them. Sometimes I even only look at problems that I’m certain I won’t solve, just to make sure that I won’t actually have to start doing the work of writing down a publication-grade solution. It seems that I still like flexing my math-muscles every now and then, but I don’t feel the need to actually get properly down to business anymore. The technical stuff with e.g. learning Python details and using it to solve problems seems to be scratching the same itch as mathematical research did, though it’s nowhere near the level of technical complexity or abstraction of math research. But it can be difficult and complex enough in other ways. And I’m happy with this. In particular as this type and level of challenges connects with some of my favorite things — sleeping in your my own bed, consistently living in the same city as my family and not having to apply for jobs every year or two.
I think that the feelings I’m getting here are comparable to a professional sportsperson of some sort — a few years ago, at the height of my postdoc period, I was the best I’ve ever been in math and the best I ever will be. I’m still very good in math, way above the 99th percentile, but I will never again have the level that comes with the singular focus you get from dedicating most of your waking hours to perfecting one topic that you’ve been practicing for over a decade. And I’m fine with this — it felt good being at the level I was, but my life as a whole feels better and more balanced now.
Epilogue
I doubt there will be a fourth part in this trilogy, mostly because I don’t really see what I could add in e.g. 5 years time that would be any different than all the career advice and stories we already have from other jaded professionals. If something actually interesting comes up, I might write about it and link it also here, but you shouldn’t wait up. Until then, good luck and keep on sciencing the data!
 Figure:
“A painting of the end.” by DALL-E (A very rare example where DALL-E gets the text right!)
Figure:
“A painting of the end.” by DALL-E (A very rare example where DALL-E gets the text right!)